
Research
My research interests include physics-aware and object-interaction video generation, with the goal of developing generative models that can better understand, capture, and simulate real-world physical dynamics. Previously, my work focused on diffusion-based generative models, with an emphasis on diffusion distillation and efficient one-step generation techniques for practical applications such as video enhancement and image inpainting. I am particularly interested in methods that maintain high generation quality while reducing computational cost, making generative AI more scalable, efficient, and accessible. I have also worked on adversarial defenses to support the safe and responsible deployment of generative video models.
Selected Publications
* denotes equal contribution
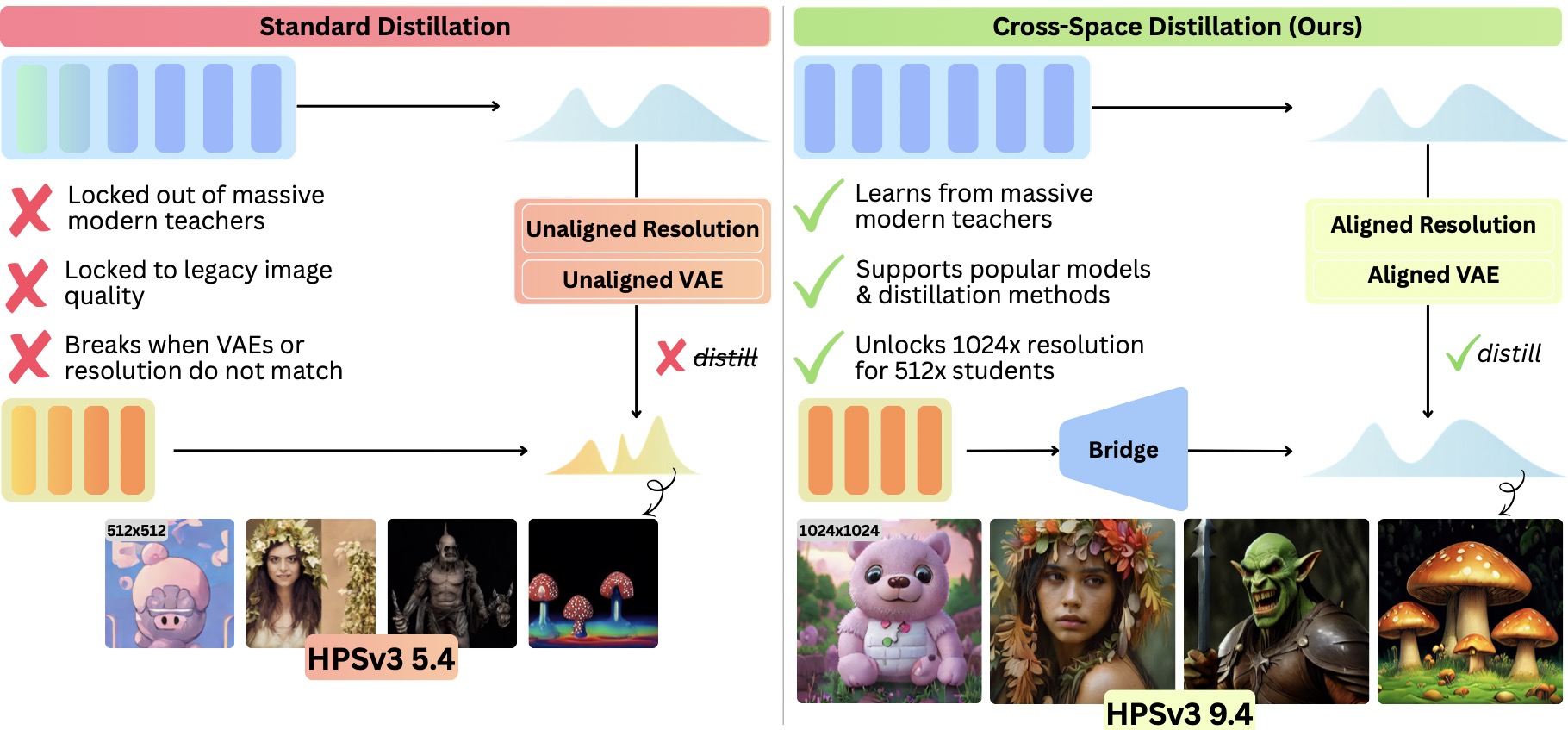
We formalize Cross-Space Distillation and introduce Bridge, a lightweight latent-space interface that makes standard one-step distillation possible across mismatched resolutions, VAEs, architectures, and diffusion/flow paradigms.
A memory-efficient adversarial attack against diverse image-to-video diffusion models, enabled by robust dual-space perturbation optimization.
A highly efficient one-step inversion diffusion network for high-quality few-step image inpainting.
iSM resolves five major shortcut-model flaws with dynamic guidance, wavelet loss, sOT, and Twin EMA, yielding markedly better image generation.
An improved SwiftBrush version that makes the one-step diffusion student beats its multi-step teacher.
A high-quality dataset centered on extreme pose faces, supporting face synthesis, reenactment, recognition benchmarking, and more.
Selected Preprints
* denotes equal contribution
A plug-and-play, backbone-agnostic video enhancer with low compute: each frame requires only inversion plus one generator pass, making it easy to deploy on outputs from diverse T2V systems.